
Полезное
•
10 минут на чтение
Поделиться статьей

Итан Уитком
Содержание
Команды обычно начинают задумываться о собственном RPC TRON, когда поведение приложения становится чувствительным к скачкам задержки, непредсказуемым rate limit’ам или задержкам в распространении транзакций. Публичные эндпоинты удобны, но они рассчитаны на широкие паттерны трафика, а не на нагрузки, которым нужны стабильные времена ответа, предсказуемая стоимость исполнения и более глубокая видимость того, как сеть обрабатывает их транзакции. Именно тогда имеет смысл и арендовать энергию TRON, чтобы стабилизировать комиссии и снизить риск того, что транзакции будут зависать из-за ограничений по ресурсам.
С выделенным узлом вы получаете стабильную производительность, полную наблюдаемость и возможность определять собственные SLO на основе реальных метрик, а не гарантий best effort. Для продакшен-систем такой дополнительный контроль часто напрямую означает меньше инцидентов и более предсказуемые релизы.
Стоит ли вообще запускать собственный узел TRON?
Решение о запуске собственного узла TRON зависит от того, насколько ваш проект чувствителен к задержкам, аптайму и прозрачности работы сети. Многие команды прекрасно обходятся публичными или управляемыми RPC-сервисами, особенно на ранних этапах, когда требования к производительности ещё невысоки. Соотнесите тип проекта с тем вариантом RPC, который даёт лучший баланс между скоростью, надёжностью и объёмом операционной работы.
Тип проекта | Рекомендуемая схема RPC | Ключевое требование, определяющее выбор |
|---|---|---|
MVP / ранний прототип | Публичный RPC | Быстрая итерация при минимальных инфраструктурных потребностях |
dApp с умеренной стабильной нагрузкой | Управляемый приватный RPC | Предсказуемая производительность без операционных накладных расходов |
Торговые боты / арбитраж | Самостоятельно размещённый узел | Стабильно низкая задержка и предсказуемое распространение |
Биржи / кастодиальные сервисы / стейкинг | Выделенный самостоятельно размещённый узел | Полный контроль над аптаймом, логированием и комплаенсом |
Аналитика / индексирование | Управляемый RPC (лёгкая нагрузка) / самостоятельно размещённый узел (тяжёлая нагрузка) | Пропускная способность и объём запросов растут вместе с объёмом данных |
Запуск собственного узла даёт вам контроль над обновлениями, производительностью и детальным мониторингом, что помогает стабилизировать продакшен-нагрузки. Обратная сторона в том, что всю операционную часть вы берёте на себя: поддержание синхронизации узла, замена оборудования и устранение проблем по мере их появления. Публичные и управляемые RPC избавляют от этой нагрузки, но ограничивают ваши возможности тонко настраивать производительность и гарантировать стабильное поведение.
Как RPC TRON работает для вашего приложения
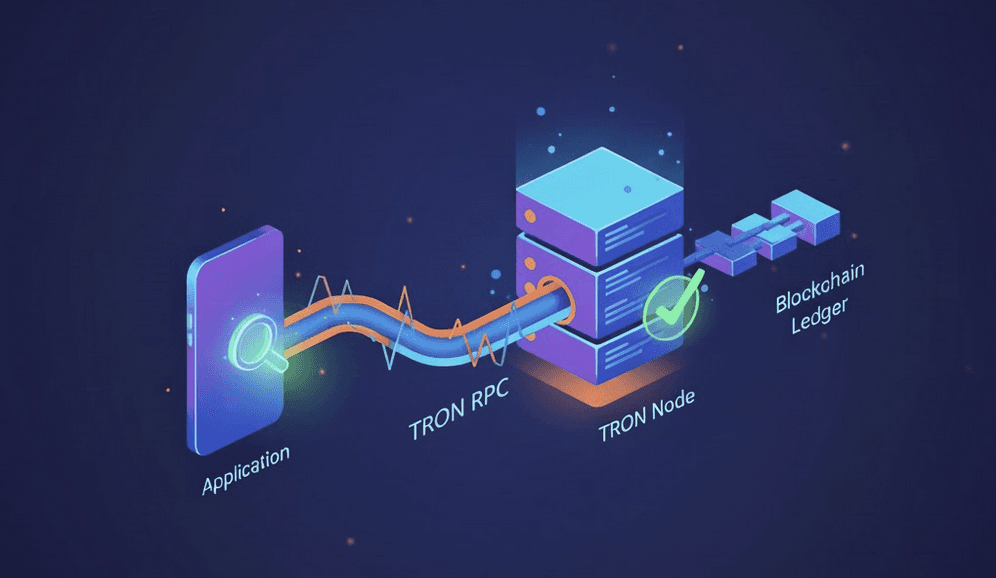
RPC TRON — это интерфейс, через который ваше приложение читает ончейн-данные и отправляет транзакции. Он работает поверх полного узла и открывает только те возможности, от которых зависит dApp: балансы, вызовы контрактов, логи и отправку транзакций. Напрямую с узлом приложение не взаимодействует. Именно слой RPC определяет, насколько быстро и надёжно ваше приложение работает с сетью.
Полные узлы, RPC-эндпоинты и ваш dApp
Полный узел хранит и валидирует блокчейн TRON, а RPC-эндпоинт — это точка входа, через которую ваш dApp запрашивает данные или отправляет транзакции. Каждый запрос, от проверки адреса до симуляции вызова контракта или трансляции подписанной транзакции, проходит через RPC. Если этот эндпоинт медленный, перегруженный или нестабильный, ваше приложение мгновенно наследует эти проблемы. Поэтому качество RPC часто важнее самого узла за ним: именно RPC — то узкое место по производительности, с которым реально соприкасается приложение.
Что вы получаете, когда RPC-эндпоинт находится под вашим контролем
Когда вы запускаете RPC самостоятельно, исчезает неопределённость общей инфраструктуры. Вы сами решаете, когда проводить обновления, как работает кэширование, какие лимиты действуют и какие метрики отслеживаются. Внешний трафик больше не влияет на вашу задержку. Можно добавить кастомное кэширование, лимиты запросов под конкретную нагрузку и более глубокую видимость на уровне транзакций, превращая RPC из чёрного ящика в полностью контролируемый эндпоинт, который можно настраивать под нужды вашего приложения.
Когда запуск собственного узла TRON действительно окупается
Самостоятельно размещённый узел TRON начинает оправдывать усилия, когда ваша нагрузка зависит от стабильной производительности, строгой надёжности или контроля, продиктованного требованиями комплаенса, — того, что публичные или управляемые RPC не могут гарантировать. Обычно переход происходит при достижении определённых порогов трафика или появлении операционных рисков: когда колебания задержки начинают влиять на торговую логику, когда rate limit’ы блокируют критически важные вызовы или когда вам нужна прозрачность распространения транзакций, которой сторонние эндпоинты не дают.
Признаки того, что вы уже переросли публичный или общий RPC:
Частые rate limit’ы, которые прерывают рабочие процессы или фоновые задачи.
Нестабильная задержка, особенно во время пикового трафика или перегрузки сети.
Задержки в распространении транзакций, которые вы не можете нормально отладить из-за ограниченного набора метрик.
Регуляторные или аудиторские требования, требующие логирования, хранения данных или трассируемости, которые невозможно обеспечить на общих эндпоинтах.
Необходимость в детальном мониторинге, например отслеживании задержек блоков, поведения мемпула или индикаторов здоровья узла.
Нестабильная производительность между окружениями, которая усложняет тестирование и планирование релизов.
Когда собственный узел TRON не даёт преимущества
Выделенный узел не приносит особой пользы для MVP, прототипов или небольших dApp’ов, потому что их трафик слишком мал, чтобы вскрыть реальные пределы производительности. Публичные или управляемые RPC справляются с такими нагрузками не хуже и не требуют обслуживания. Командам без DevOps- или SRE-ресурсов тоже лучше не запускать свой узел, поскольку поддержание синхронизации, обновления и мониторинга требует постоянных усилий. Если редкие задержки или ограничения общего RPC не влияют на ваших пользователей и бизнес-логику, собственный узел лишь добавит затрат и сложности без ощутимой пользы.
Продакшен-архитектура TRON RPC
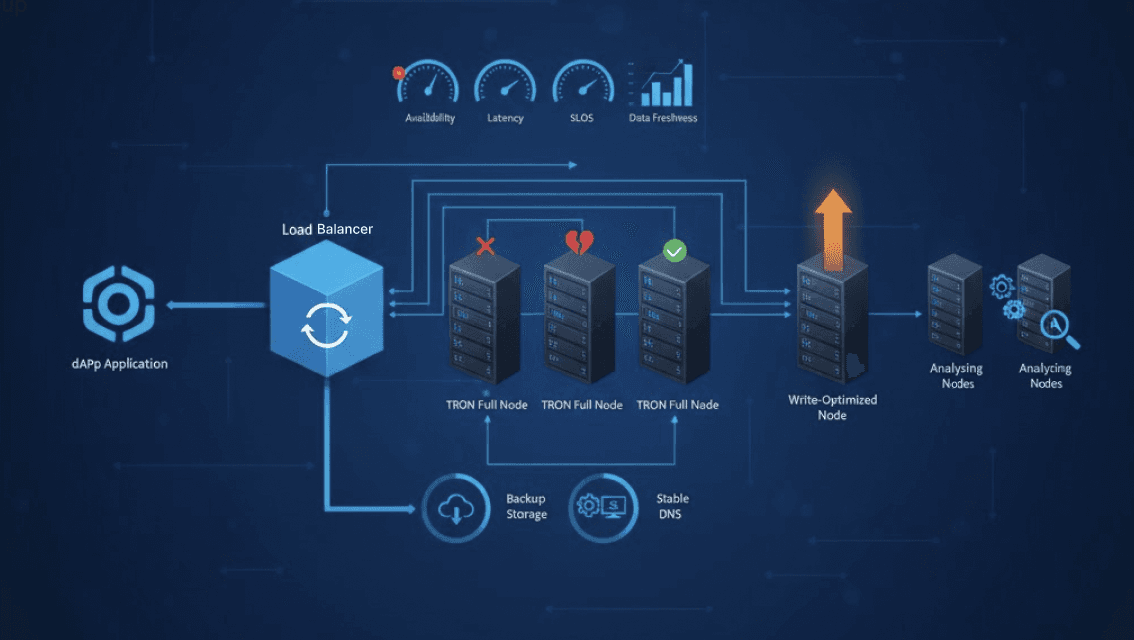
Продакшен-архитектура RPC TRON проектируется с расчётом на скорость и доступность во время сбоев узлов или всплесков трафика. Отправная точка — один тщательно мониторируемый узел со стабильным эндпоинтом. Чтобы справляться с ростом нагрузки и сохранять отзывчивость dApp’а во время простоев или проблем с синхронизацией, архитектура должна масштабироваться за счёт добавления нескольких узлов.
Базовая архитектура с одним узлом
Минимальная продакшен-конфигурация — это один полный узел, который также публикует RPC-эндпоинт. Узел размещается за стабильным DNS-адресом, чтобы приложение не было привязано к его внутреннему IP. Резервное копирование должно охватывать конфигурацию, снапшоты состояния цепочки и данные мониторинга, чтобы обеспечить быстрое восстановление при поломке хранилища или оборудования. Такая схема подходит для небольших нагрузок, которым нужна стабильная задержка, но не требуется высокая доступность.
Кластер TRON RPC с высокой доступностью
Конфигурация высокой доступности использует несколько узлов за балансировщиком нагрузки. Узлы могут работать в режиме active-active, когда все одновременно обслуживают запросы, или active-passive, когда резервные узлы принимают трафик только при отказе основного. Проверки состояния отслеживают статус синхронизации, задержку и уровень ошибок, чтобы исключать деградировавшие узлы из ротации.
Паттерны масштабирования: read-heavy, write-heavy и analytics
Разные типы нагрузки масштабируются за счёт назначения узлам специализированных ролей. Сценарии с преобладанием чтения работают быстрее, когда несколько полных узлов параллельно обрабатывают запросы. Системы с преобладанием записи, включая торговые нагрузки, показывают лучшие результаты, когда один узел настроен на максимально быструю трансляцию транзакций. Аналитические и индексирующие пайплайны должны работать на отдельных узлах, чтобы не конкурировать с продакшен-RPC-трафиком. Такое разделение ролей убирает взаимное влияние нагрузок и помогает сохранять стабильную задержку по мере роста системы.
Определение SLO для вашего TRON RPC
SLO задают измеримые целевые параметры того, как ваш TRON RPC должен вести себя в продакшене. Они определяют, насколько доступным должен быть эндпоинт, как быстро он обязан отвечать, насколько свежими должны оставаться данные цепочки и какое количество ошибок ваше приложение может допустить без влияния на пользователей.
Ключевые измерения SLO: доступность, задержка, свежесть, ошибки
SLO для TRON RPC обычно измеряют четыре вещи:
Доступность: процент времени, в течение которого RPC должен успешно отвечать; обычно от 99,5% до 99,9% в зависимости от типа нагрузки.
Задержка: целевые значения p95 и p99 для операций чтения и записи; например, p95 ниже 150 мс для чтения и ниже 250 мс для трансляции транзакций.
Свежесть данных: насколько узлу разрешено отставать по высоте блока; для продакшена обычно не более 1–2 блоков.
Уровень ошибок: допустимая доля неуспешных запросов; как правило, менее 0,1% для стабильных dApp’ов и почти ноль для торговых систем.
Примеры SLO для типовых нагрузок TRON
Разные приложения на TRON предъявляют разные требования к своему RPC-эндпоинту, поэтому каждой категории нужны собственные целевые SLO по доступности, задержке и свежести данных.
Тип нагрузки | Цель по доступности | Цель по задержке | Свежесть данных | Операционное требование |
|---|---|---|---|---|
DeFi-протоколы | 99,9% | Жёсткий p95 (чтение около 150 мс) | Максимальное отставание 1–2 блока | Для логики ценообразования, исполнения и ликвидаций требуется точное состояние сети. |
NFT-платформы | 99,5–99,9% | Умеренный p95 | Низкое или умеренное отставание | Минтинг и действия маркетплейса должны оставаться надёжными под нагрузкой. |
Торговые боты / арбитраж | Почти 100% рабочего времени | Очень строгий p99 (<150–200 мс) | Почти нулевое отставание | Алгоритмы исполнения зависят от быстрых и точных данных сети. |
Аналитика / индексирование | 99%+ | Более низкий приоритет | Строгая актуальность по высоте блока | Устаревшие данные блоков ломают пайплайны и снижают точность датасетов. |
Соотнесение SLO с архитектурными решениями
Ваши целевые SLO определяют, какой объём инфраструктуры вам нужен. Выбирайте самую простую конфигурацию, которая способна надёжно обеспечить ваши цели по доступности, задержке и свежести данных.
Один узел подходит для умеренных требований к доступности и стабильного трафика.
HA-кластер нужен для высокой доступности и низкого бюджета ошибок; он устраняет единые точки отказа.
Read-ноды помогают выдерживать жёсткие требования по задержке в сценариях с преобладанием чтения.
Write-ноды повышают скорость распространения транзакций для торговых и автоматизированных систем.
Analytics-ноды изолируют индексирование, чтобы производительность продакшен-RPC оставалась стабильной.
Региональные реплики снижают задержку для глобальной аудитории.
По мере роста требований к SLO архитектуре требуется больше резервирования, разделения ролей и контроля.
Эксплуатация собственного узла TRON: мониторинг и риски
Чтобы узел TRON работал стабильно в продакшене, нужно следить за его поведением под нагрузкой и понимать операционные риски ещё до перехода на self-hosted-схему. Хороший мониторинг предотвращает простои, а ясная оценка соотношения затрат и рисков помогает не построить инфраструктуру, которую команда не сможет реально поддерживать.
Основа мониторинга и алертинга
Продакшен-узлу нужен непрерывный мониторинг метрик, которые напрямую влияют на ваше приложение, включая:
использование CPU и памяти, чтобы выявлять перегрузку или насыщение ресурсов;
задержку для операций чтения и записи, особенно p95 и p99;
уровень ошибок, рост которого сигнализирует о проблемах синхронизации или RPC;
отставание от сети (chain lag), измеряемое как разница между вашим узлом и текущим состоянием сети.
Алерты должны срабатывать, когда эти метрики пересекают заданные пороги, чтобы у вас было время масштабировать систему, перезапустить узел или устранить проблему до того, как её заметят пользователи.
Проверка затрат и рисков перед запуском
Самостоятельный хостинг добавляет и расходы, и операционную нагрузку. Вы платите за железо или облачные ресурсы, рост объёма хранилища, трафик и бэкапы, а также нуждаетесь в людях, которые смогут поддерживать узел. Ответственность за аптайм, обновления и реагирование на инциденты в любое время тоже ложится на вас. Перед запуском стоит сопоставить эти издержки с выгодой от меньшей задержки и полного контроля. Если преимущества неочевидны, управляемый RPC обычно оказывается более выгодным вариантом.
Стоит ли запускать собственный узел TRON?
Self-hosted RPC TRON становится полезным, когда вашей системе нужна более надёжная производительность и более глубокая наблюдаемость, чем могут дать публичные или управляемые эндпоинты. До этой точки первыми обычно доходят такие нагрузки, как биржи, кастодиальные платформы, торговые движки и тяжёлая аналитика, потому что они зависят от стабильной задержки, быстрого распространения транзакций и постоянного доступа к свежим данным. Когда ваши SLO включают высокую доступность, строгие требования к p95/p99 и минимальное отставание по блокам, архитектура с отдельными узлами для чтения, записи и аналитики даёт нужный уровень контроля и помогает оставаться в рамках бюджета.
Более лёгкие нагрузки не получают такой же выгоды. MVP, небольшие dApp’ы и команды без выделенной DevOps-поддержки могут избежать лишних накладных расходов, используя управляемый RPC. Переход на self-hosted-архитектуру имеет смысл только тогда, когда производительность и надёжность напрямую влияют на продукт. Лучше всего выбирать такую архитектуру, которая закрывает ваши SLO при минимальных операционных затратах.
Новые статьи




