
Éducation
•
10 minutes de lecture
Partager l'article

Ethan Whitcomb
Table des matières
Teams usually start considering their own TRON RPC when the app’s behavior becomes sensitive to latency spikes, unpredictable rate limits, or delayed transaction propagation. Public endpoints are convenient, but they’re built for broad traffic patterns — not workloads that need consistent response times, predictable execution costs, and deeper visibility into how the network treats their transactions. That’s also when it makes sense to rent tron energy to stabilize fees and reduce the risk of transactions stalling under resource constraints.
With a dedicated node, you gain stable performance, full observability, and the ability to define your own SLOs based on real metrics rather than best-effort guarantees. For production systems, that added control often translates directly into fewer incidents and more predictable releases.
Should you run your own TRON node at all?
Deciding whether to run your own TRON node depends on how sensitive your project is to latency, uptime, and network visibility. Many teams do perfectly well with public or managed RPC services, especially in early stages where performance requirements are low. Match your project type with the RPC setup that gives the best balance of speed, reliability, and operational effort.
Project Type | Recommended RPC Setup | Core Requirement Driving the Choice |
MVP / Early Prototype | Public RPC | Fast iteration with minimal infrastructure needs. |
dApp with Moderate Steady Usage | Managed Private RPC | Predictable performance without operational overhead. |
Trading Bots / Arbitrage | Self-Hosted Node | Consistent low latency and stable propagation. |
Exchanges / Custodial / Staking | Dedicated Self-Hosted Node | Full control over uptime, logging, and compliance. |
Analytics / Indexing | Managed RPC (light) / Self-Hosted Node (heavy) | Throughput and request volume scale with data size. |
Running your own node gives you control over updates, performance, and detailed monitoring, which helps stabilize production workloads. The trade-off is that you must handle the operational side yourself: keeping the node synced, replacing hardware, and fixing issues when they appear. Public and managed RPCs avoid this overhead but limit your ability to fine-tune performance or guarantee consistent behavior.
How TRON RPC Works for Your Application
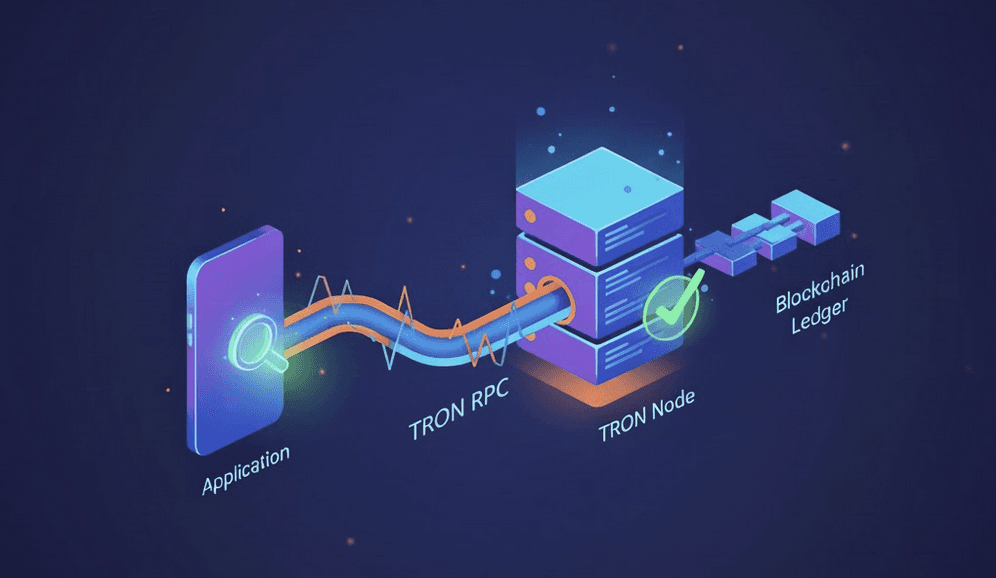
A TRON RPC is the interface your application uses to read on-chain data and send transactions. It sits on top of a full node and exposes only the capabilities a dApp depends on: balances, contract calls, logs, and transaction submission. You don’t deal with the node directly. The RPC layer determines how fast and how reliably your app interacts with the network.
Full nodes, RPC endpoints, and your dApp
A full node stores and validates the TRON blockchain, while the RPC endpoint is the entry point your dApp calls to fetch data or push transactions. Every request, from checking an address to simulating a contract call or broadcasting a signed transaction, passes through the RPC. If this endpoint is slow, overloaded, or inconsistent, your dApp inherits those issues instantly. That’s why RPC quality often matters more than the node behind it: it’s the performance bottleneck your app actually touches.
What you gain when the RPC endpoint is under your control
Running the RPC yourself removes the uncertainty of shared infrastructure. You decide when upgrades happen, how caching works, what limits apply, and which metrics are tracked. No outside traffic affects your latency. You can add custom caching, workload-specific rate limits, and deeper transaction-level visibility, turning the RPC from a black box into an endpoint you fully control and can tune to your app’s needs.
When running your own TRON node actually pays off
A self-hosted TRON node becomes worth the effort once your workload depends on consistent performance, strict reliability, or compliance-driven control that public or managed RPCs can’t guarantee. The shift normally happens at specific traffic thresholds or operational risks: when latency variations affect trading logic, when rate limits block critical calls, or when you need visibility into propagation that third-party endpoints don’t expose.
Signs you’ve outgrown public or shared RPC:
Frequent rate limits that interrupt workflows or background jobs.
Unstable latency, especially during peak traffic or network congestion.
Transaction propagation delays you can’t troubleshoot due to limited metrics.
Regulatory or audit requirements that demand logging, retention, or traceability you cannot enforce on shared endpoints.
Need for fine-grained monitoring, such as tracking block delays, mempool behavior, or node health indicators.
Inconsistent performance between environments that complicates testing and release planning.
When is having your own TRON node an advantage?
A dedicated node is not useful for MVPs, prototypes or small dApps because their traffic is too low to expose performance limits. Public or managed RPCs handle these workloads just as well and require no maintenance. Teams without DevOps or SRE capacity should also avoid running their own node since keeping it synced, updated and monitored takes ongoing effort. If occasional delays or shared RPC constraints do not affect your users or business logic, operating your own node will add cost and complexity without giving practical benefits.
TRON RPC production setup
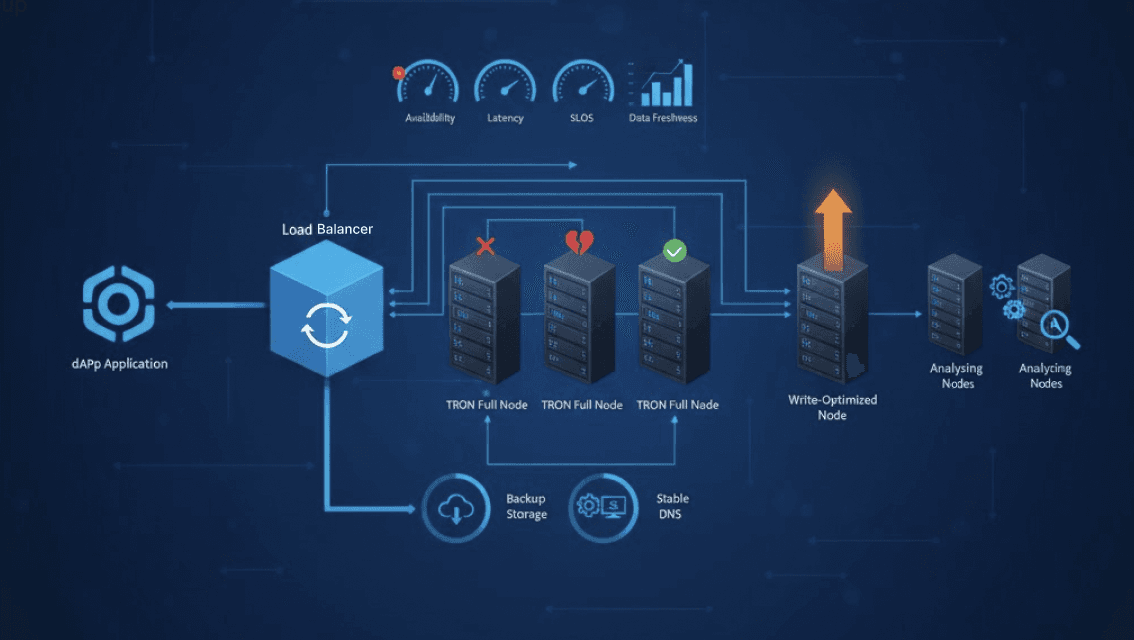
A production TRON RPC setup is designed for speed and availability during node failures or traffic spikes. The starting point is a single, heavily monitored node with a stable endpoint. To handle increasing load and ensure dApp responsiveness during downtime or syncing issues, the setup must scale by adding multiple nodes.
Baseline single-node architecture
A minimal production setup is one full node that also exposes the RPC endpoint. The node sits behind a stable DNS address so the application is not tied to its internal IP. Backups cover configuration, chain data snapshots, and monitoring data to allow fast recovery if storage or hardware breaks. This setup fits small workloads that need consistent latency but do not require high availability.
Highly-available TRON RPC cluster
A high-availability setup runs multiple nodes behind a load balancer. Nodes can operate in active–active mode, where all serve requests, or active–passive, where secondary nodes take over only if the primary fails. Health checks monitor sync status, latency, and error rates to remove degraded nodes from rotation.
Scaling patterns: read-heavy, write-heavy, and analytics
Different workloads scale by assigning nodes specific roles. Read-heavy traffic runs faster when multiple full nodes serve queries in parallel. Write-heavy systems, including trading workloads, perform better when one node is tuned for fast transaction broadcast. Analytics and indexing pipelines work on separate nodes so they do not compete with production RPC traffic. Isolating these roles removes contention and keeps latency stable as the system grows.
Defining SLOs for your TRON RPC
Service-level objectives give you measurable targets for how your TRON RPC should behave in production. They define how available the endpoint must be, how fast it must respond, how fresh the chain data must stay, and how many errors your application can tolerate without user impact.
Core SLO dimensions: availability, latency, freshness, errors
SLOs for TRON RPC usually measure four things:
Availability: The percentage of time the RPC must respond successfully, often 99.5% to 99.9% depending on workload.
Latency: p95 and p99 targets for read and write operations, for example p95 under 150 ms for reads and under 250 ms for transaction broadcasts.
Freshness: How far behind the node is allowed to be in block height, often no more than 1–2 blocks for production use.
Error rate: Acceptable percentage of failed requests, typically under 0.1% for stable dApps and near zero for trading systems.
Example SLOs for common TRON workloads
Different TRON applications place different demands on their RPC endpoint, so each category needs its own SLO targets for availability, latency, and data freshness.
Workload Type | Availability Target | Latency Target | Data Freshness | Operational Requirement |
DeFi protocols | 99.9% | Tight p95 (around 150 ms reads) | 1-2 blocks max lag | Accurate state access is required for pricing, execution and liquidation logic. |
NFT platforms | 99.5–99.9% | Moderate p95 | Low to moderate lag | Minting and marketplace actions must stay reliable under load. |
Trading bots / arbitrage | Close to 100% operational time | Very strict p99 (<150–200 ms) | Near-zero lag | Execution algorithms depend on fast, precise chain data. |
Analytics / indexing | 99%+ | Lower priority | Strict block height freshness | Stale block data breaks pipelines and reduces dataset accuracy. |
Mapping SLOs to architecture choices
Your SLO targets determine how much infrastructure you need. Choose the simplest setup that can reliably meet your availability, latency and freshness goals.
Single node works for moderate availability and stable traffic.
HA cluster needed for high availability and low error budgets; removes single points of failure.
Read nodes support tight latency for read-heavy workloads.
Write nodes improve propagation speed for trading and automation systems.
Analytics nodes isolate indexing so production RPC performance stays stable.
Regional replicas reduce latency for global users.
As SLO expectations rise, the architecture requires more redundancy, role separation and control.
Operating your own TRON node: monitoring and risk
To keep a TRON node stable in production, you need to watch how it behaves under load and understand the operational risks before moving to a self-hosted setup. Good monitoring prevents outages, and a clear cost-risk assessment helps avoid infrastructure your team cannot realistically support.
Monitoring and alerting essentials
A production node needs continuous monitoring of the metrics that directly affect your application, including:
CPU and memory usage, to detect overload or resource saturation.
Latency for read and write calls, especially p95 and p99.
Error rate, which signals sync or RPC issues as it rises.
Chain lag, measured as the gap between your node and the network tip.
Alerts should fire when these metrics cross defined thresholds so you can scale, restart or repair before users notice issues.
Cost and risk check before you commit
Self-hosting adds both cost and operational duty. You pay for hardware or cloud resources, storage growth, bandwidth and backups, and you also need people who can maintain the node. You become responsible for uptime, updates and incident response at all hours. Before committing, weigh these costs against the value of lower latency and full control. If the benefits are not clear, a managed RPC is the more profitable option.
Is it worth launching your own TRON node?
A self-hosted TRON RPC becomes useful once your system needs reliable performance and more insight than public or managed endpoints can provide. Workloads like exchanges, custodial platforms, trading engines and heavy analytics often reach that point first, because they depend on steady latency, fast propagation and consistent access to fresh data. When your SLOs include high availability, strict p95/p99 latency and tight block freshness, a layout with separate read, write and analytics nodes gives you the control needed to stay within budget.
Lighter workloads do not benefit in the same way. MVPs, small dApps or teams without dedicated DevOps support avoid unnecessary overhead by using managed RPC. The upgrade to a self-hosted setup makes sense only when performance and reliability directly affect the product. It is best to choose an architecture that meets your SLOs with minimal operational costs.
Liens : Assistance | Bot
Dernière publication




